
- dev
- ops
- football
- making lists
Categories
Archives
- April 2013 (1)
- November 2010 (1)
- March 2010 (1)
- December 2008 (1)
- October 2008 (1)
- September 2008 (1)
About
sayap is a code monkey who writes long ticket description and even longer commit message to bore future maintainer to death.
sayap lives in Malaysia, and follows timezone
EPL/Arsenal.

Mythtv's xmltv grabber for Malaysia channels
December 30, 2008 at 11:08 PM | categories: python, boleh, linux | View CommentsEver since I got mythtv up and running months ago, I have always wanted to use the Electronic Program Guide (EPG) feature. Unfortunately, getting tv schedules in a format understandable by mythtv (i.e. xmltv) is not so easy.
From a bit of googling, I found 2 (non-)solutions. The first one involves using tvxb through wine to grab tv schedules from Astro through screenscraping. Apparently, it doesn't work anymore, as the tvxb site is showing the following message:
All Astro satellite channels (No longer works - needs updating. 2008/10/12)
The other solution is a perl script written by Shahada Abubakar that also screenscrapes Astro listing. Like the first one, this solution has also ceased to be working, due to the flaky nature of screenscraping.
Of course, the googling and testing were just unnecessary foreplay. I was set at the beginning to come up with my own solution anyway. With the help of wonderful python libraries such as BeautifulSoup and lxml, I wrote a xmltv grabber that:
-
can screenscrape either Astro or The Star listings for channels rtm1, rtm2, tv3, ntv7, 8tv, and tv9
-
is functioning as of 2008-12-31 (UPDATE: broken as of 2013-01-27, ugh)
Here's the script: grabmy.py
To get it to work, install the requirements first:
easy_install BeautifulSoup lxml httplib2 python_dateutil
Then, run the script to generate a xmltv file:
python grabmy.py -f my.xml
Feed mythbackend with the file:
mythfilldatabase --file 1 my.xml
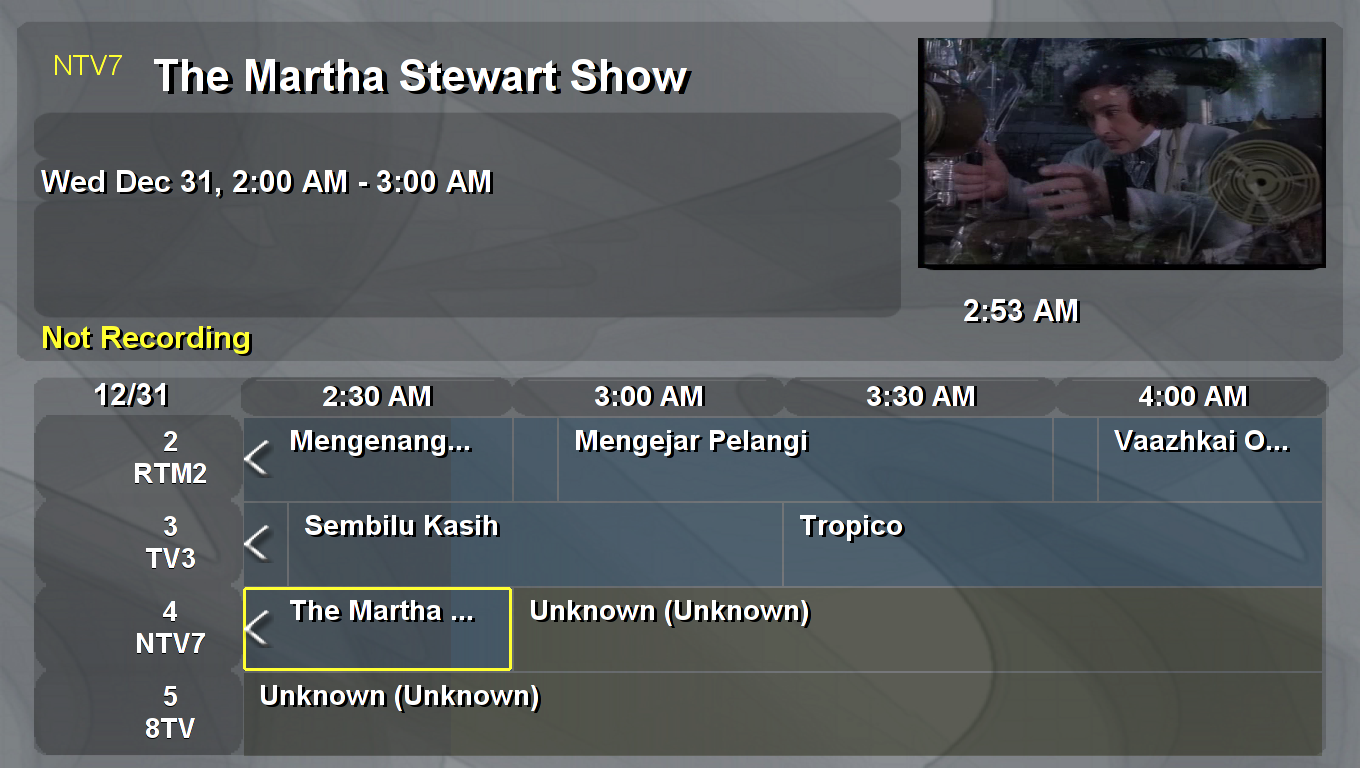
And finally, here's the EPG in its full glory if you channel-flip at 2am:
JavaScript: The ManBearPig of Programming Language
October 20, 2008 at 09:09 AM | categories: javascript | View CommentsIn the last few days, I got the chance to play with a bit of JavaScript at work. As someone who has near zero JavaScript experience, it appeared to me that it is a language with little conceptual integrity. Some examples:
-
Objects are associative arrays, but unlike arrays, they don't have any helper function or attribute (because objects are associative arrays). It says a lot about the language design when arrays have reduce() while associative arrays do not even have length.
-
There is no function overloading, and default parameter can't be specified either. Fear not - you are blessed with the magical arguments, and the warm and fuzzy feeling from coding a command line app.
-
JavaScript 1.8 added a lambda notation that gave the braces another meaning. A pair of braces create an object. A pair of braces also form a code block. If your have a one-line function followed by an opening brace, you need a return. Otherwise, you don't.
-
jQuery has a each function that associates a
truereturn value as continue and afalsereturn value as break. prototype has a each function that used to associate a$continueexception as continue and a$breakexception as break. Desperately wanting a piece of "anonymous function does not always return a value" warning, it now associates any return value as continue. -
Python got PEP8, Java got code convention, JavaScript got sparse style guides that do not conform to each other. Nobody seems to referring to them anyway.
In short, there is no equivalent word for Pythonic in the land of JavaScript. As a programming language, JavaScript is just like ManBearPig, with limbs and body parts from different animals attached together at random to create the ferocious monster:

Not unlike ManBearPig, people easily get confused when it comes to defining JavaScript. Is it half man-bear, half pig? Or is it half man, half bear-pig? Look at this question posted at stackoverflow, seeking the real identity of JavaScript:
There have been some questions about whether or not JavaScript is an object-oriented language. Even a statement, "just becuase a language has objects doesn't make it OO ".
Is JavaScript an object oriented language?
And here's my favorite answer with a +8 (emphasis mine):
Javascript is a multi-paradigm language that supports procedural, object-oriented (prototype-based) and functional programming styles.
Half man, half bear, half pig. That's a ManBearPig in my book.
Of course, by rephrasing a little, we can get a more correct answer:
JavaScript is a programming language that looks pretty much object-oriented, but aspiring to be a functional one, yet being used the most to create procedural code.
Trying to clean up the image of JavaScript, Douglas Crockford kept telling us that JavaScript is the world's most misunderstood programming language. Which is, of course, the same as saying ManBearPig is the world's most misunderstood animal. Duh.
Anyway, enough with the JavaScript bashing, which is not the point of this post. You see, this is all part of Al Gore's effort to spread ManBearPig awareness. Al Gore invented the Internet, which then gave birth to JavaScript that closely resembles the evilness of ManBearPig. He just wanted to subtlely tell the world how dangerous ManBearPig is, by giving us this reckless languauge called JavaScript. Thus, let me end this by saying:
"Thank you, Al Gore. You are super awesome."
How to start a blog
September 19, 2008 at 09:59 PM | categories: meta, boleh | View CommentsHere's how a normal person starts a blog:
-
Make a coin toss. Heads for wordpress, tails for blogger, middle for others.
-
Sign up.
-
Blog like a normal person.
Of course, blogging like a normal person is pretty boring. For one, if you blog like a normal person, you won't even get arrested under ISA. Boring. * yawn *
So here's how a real man starts a blog:
-
Spend a few days looking for a server that is cheap, fast, and has a reasonably not-slow connection to whatever 3rd world country that you happens to live in.
-
Call your credit card company to authorize the payment for the server, all the while resisting the urge to explain that the transaction is not for porn.
-
Spend a few days looking for a blog software that doesn't have any freaking release yet, let alone a stable one. Spend a few nights setting it up -- in a 3rd world country, you get slightly less sucky connection in the off-peak hours.
-
Realize that unstable really does mean unstable, and the software is just unuseable. Nonsense. A magical touch of
hg revert -r 486 .makes it production ready, and you are good to go. -
Blog about how to start a blog (to mask the fact that you have totally forgotten what you wanted to blog about in the first place).